Questa trilogia di post tratta la raccolta dei dati di stampa da più fonti, per la creazione di report e l’analisi. Nella prima parte abbiamo parlato della raccolta dei dati e di come evitare “buchi neri” nei dati di stampa. Nella seconda parte abbiamo esaminato la produzione, la pianificazione e la consegna di report per attività quali il riaddebito delle fatture, l’allocazione dei costi e la creazione di semplici report di riepilogo utili per la gestione. In quest’ultima parte, vedremo in che modo in che modo l’analisi può fornire visibilità sui dati e ulteriori approfondimenti.
Finora si è parlato della raccolta e del reporting dei dati, utilizzando i metodi tipici delle soluzioni di gestione della stampa, ma tralasciando il modo in cui le informazioni vengono archiviate ed elaborate. Tali soluzioni di reporting si basano in genere su database SQL, che vengono utilizzati per entrambe le funzionalità operative e di reporting del software. Questo può causare potenziali conflitti tra le attività di reporting e di stampa, soprattutto nei sistemi di grandi dimensioni in cui l’esecuzione dei report richiede molto tempo: in fin dei conti mai e poi mai vorreste scoprire che proprio l’esecuzione dei report ha provocato un rallentamento o addirittura l’interruzione delle attività di stampa!
In un anno, un’azienda può generare decine di milioni di eventi di stampa e nell’arco di cinque anni potrebbe dover archiviare almeno duecento milioni di eventi di stampa. A questi livelli, per garantire un’analisi efficace dei dati può essere necessario ottimizzare la progettazione del database e delle funzionalità di reporting. Per farsi un’idea della differenza di prestazioni tra le diverse opzioni disponibili, il grafico di seguito mostra i tempi di elaborazione e rendering per lo stesso set di dati, con cinque milioni di record, in tre formati diversi. La barra rossa nella parte inferiore mostra i dati archiviati in tabelle SQL standard; quella gialla mostra un Data Warehouse con schema “a stella”, e infine quella verde in alto mostra i dati elaborati in un Cubo di SQL Analysis.
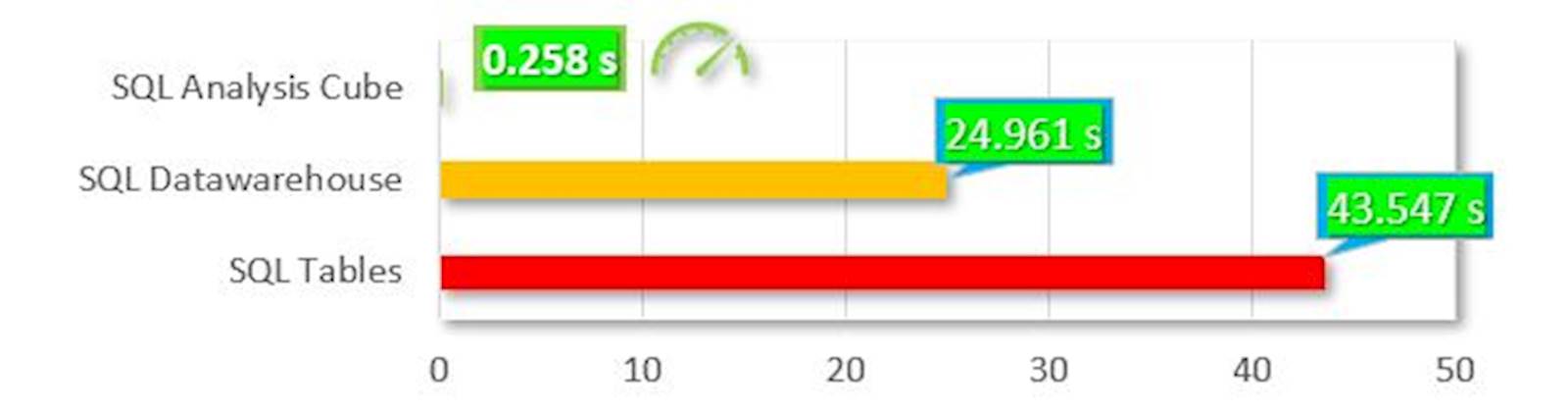
Questo grafico è sorprendente, e introduce un nuovo concetto: i cubi OLAP Un cubo OLAP (OnLine Analytical Processing) è una struttura di dati che consente un’analisi molto rapida in base alle diverse dimensioni che definiscono un problema aziendale. Ad esempio, un cubo multidimensionale per il report dei dati di stampa potrebbe essere composto da sei dimensioni: Nome utente, Reparto, Ubicazione, Tipo di stampa, Mese e Anno per le metriche di Costo totale e Impressioni totali.
La disposizione dei dati in cubi supera un limite dei database relazionali, che non sono adatti per l’analisi quasi istantanea e la visualizzazione di grandi quantità di dati. Esistono molti strumenti per la scrittura di report per database relazionali. Ma si rivelano lenti quando viene richiesto un riepilogo dell’intero database, e complessi se si vuole modificare l’orientamento dei report o analizzarli in base a prospettive multidimensionali diverse, ad esempio in “slice”. I cubi, invece, facilitano questo tipo di interazione rapida tra utente finale e dati.
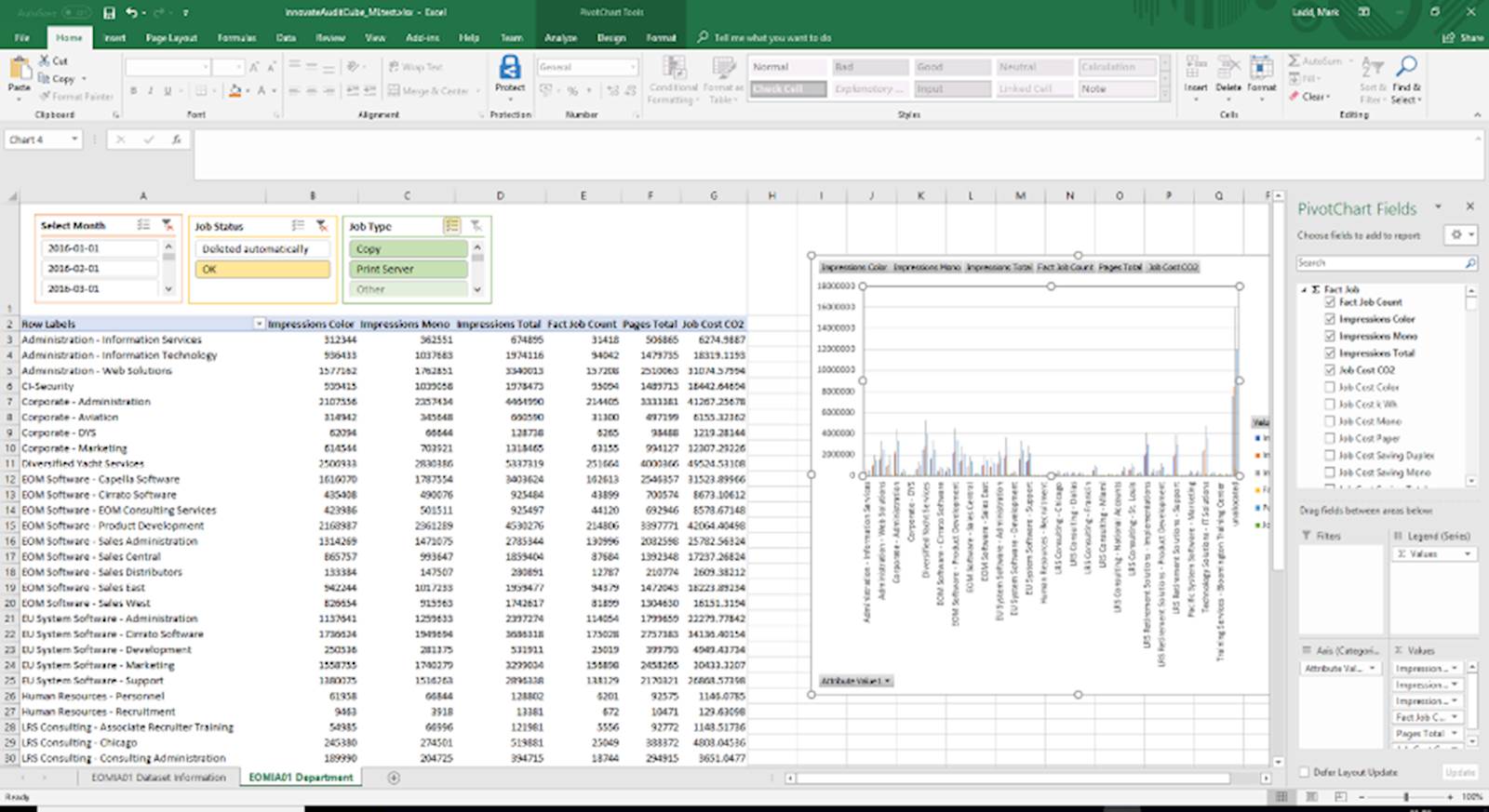
I Cubi OLAP non solo raccolgono rapidamente i dati riepilogativi dei rapporti tabellari, ma, se abbinati a una tabella pivot di Excel, sono anche in grado di fornire un’analisi estremamente potente e rapida dei dati a chiunque abbia un minimo di competenza Excel. Data Slicer, filtri e grafici pivot migliorano la presentazione dei dati in pochi secondi. L’accesso viene concesso dal motore di Analytics mediante oggetti Active Directory ed è completamente separato dalle autorizzazioni di SQL Server.
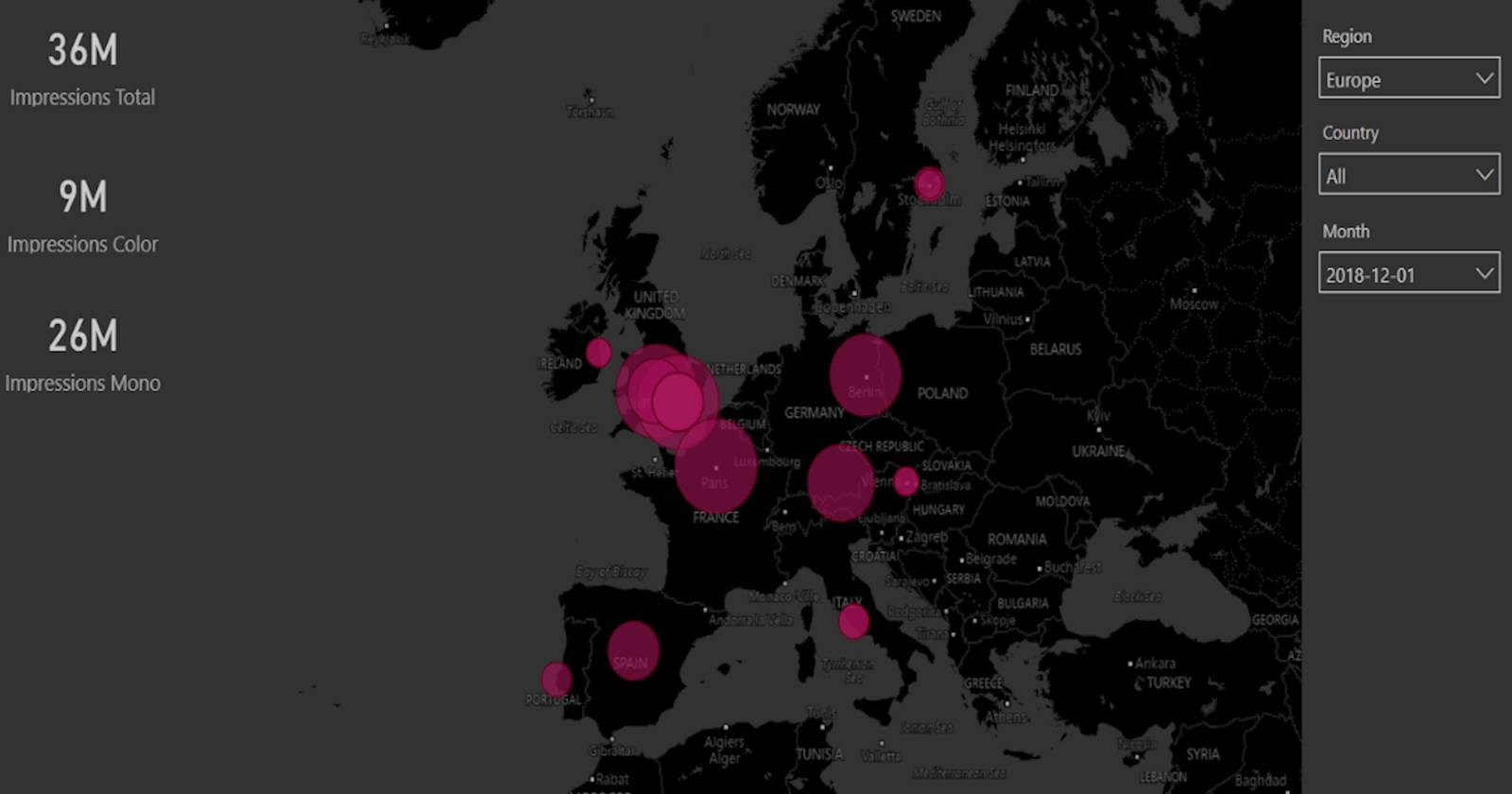
La presentazione grafica dei dati offre una visione reale e immediata. Associata alla velocità di elaborazione dei cubi OLAP, consentono di esplorare l’utilizzo della stampa in modo interattivo. L’esempio di seguito ottenuto con Power BI mostra una mappa generata dinamicamente, in cui i punti dati riflettono i volumi di stampa totali con filtri per Regione, Paese e Mese. L’utente può eseguire zoom e panoramiche sulla mappa, e il selettore Regione/Paese filtra i risultati secondo l’interesse dell’utente. Passando il puntatore del mouse sulle aree termiche della mappa verranno visualizzate ulteriori informazioni.
La struttura di Power BI consente di creare dashboard dinamiche, con una combinazione di componenti che visualizzano dati importanti per l’organizzazione. Le singole tessere possono fungere da filtri per l’intero set.
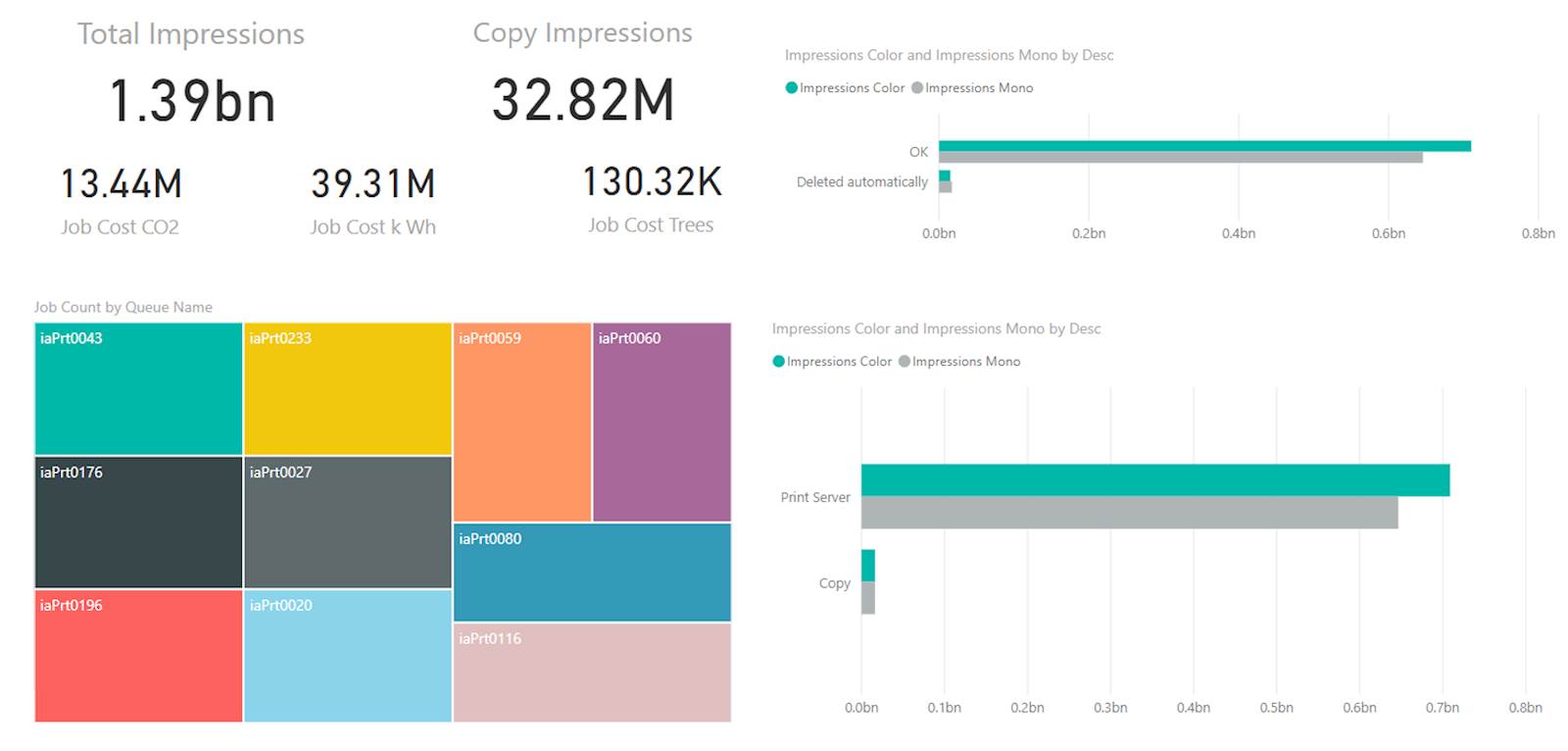
Questi strumenti consentono di creare dashboard personalizzate, rilevanti per i destinatari e con numerosi “oggetti visivi”. Un ulteriore vantaggio è la massiccia presenza di oggetti visivi personalizzati da esplorare, quali infografiche e grafici sparkline e sankey. Se un’immagine vale più di mille parole... allora una dashboard vale più di mille report tabellari (almeno per chi non è commercialista o contabile)! Power BI di Microsoft ha aperto le porte della Business Intelligence, ma anche molti altri strumenti (ad esempio Tableau) offrono l’integrazione OLAP.
Siamo giunti al termine di questa serie di post. Nel male o nel bene? Dipende dal vostro punto di vista. Mi auguro che questi articoli vi abbiano stimolato ad approfondire l’andamento delle attività di stampa nella vostra organizzazione, e a creare report personalizzati di maggior valore e realmente informativi.
[TL;DR] I rapporti tabellari standard vanno bene ma per un’analisi più efficace si può fare di più. Chiedete a LRS… possiamo darvi una mano.